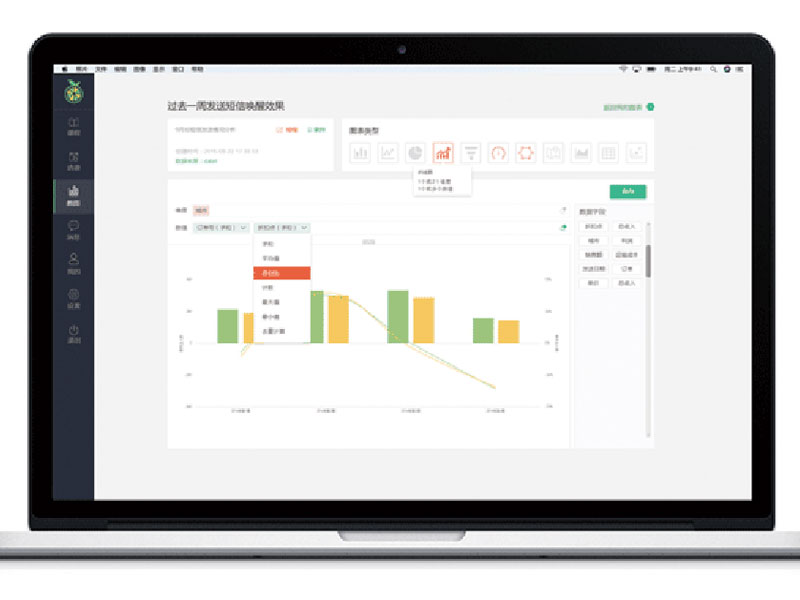
该平台拥有(yǒu)大量大数据实验室高校用(yòng)户,多(duō)所高校参与师资培训,荣获优秀项目奖等。拥有(yǒu)大数据可(kě)视化系统、数据采集系统、大数据资源管理(lǐ)系统、大数据分(fēn)析系统等大数据实验科(kē)研平台系统。
该平台拥有(yǒu)大量大数据实验室高校用(yòng)户,多(duō)所高校参与师资培训,荣获优秀项目奖等。拥有(yǒu)大数据可(kě)视化系统、数据采集系统、大数据资源管理(lǐ)系统、大数据分(fēn)析系统等大数据实验科(kē)研平台系统。
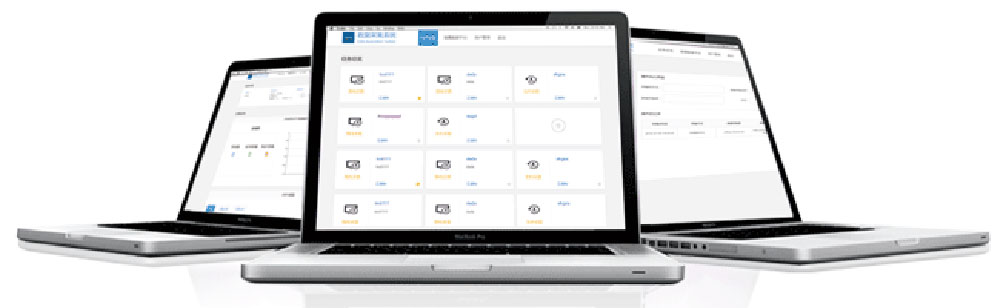
支持快速创建和一键删除采集任務(wù)、支持离線(xiàn)数据采集、支持实时数据采集、实时采集支持自定义采集节点和汇聚节点、实时采集支持实时监控HDFS的数据采集量、支持用(yòng)户管理(lǐ)、支持快速采集数据到HDFS、采集系统底层采用(yòng)Flume采集组件、图形化界面操作(zuò),简易,方便。
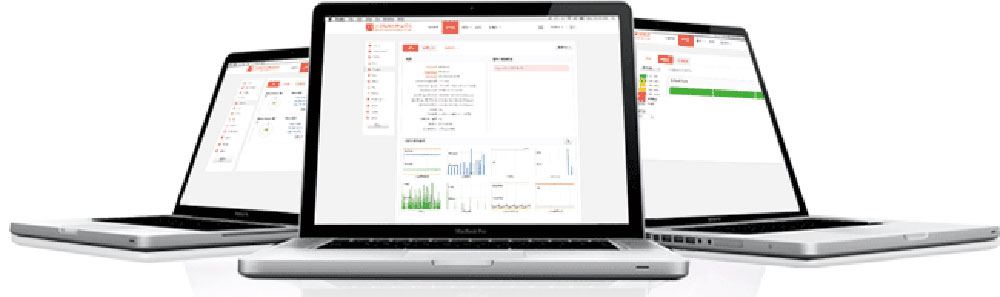
支持通过Web界面实现自动化构建Hadoop生态體(tǐ)系圈、采用(yòng)分(fēn)布式架构、支持自定义主界面和服務(wù)界面仪表盘、支持实时监控集群各服務(wù)的状态、支持浏览集群运行过的历史命令和相关日志(zhì)、支持对多(duō)个不同的集群进行管理(lǐ)、支持HDFS容量实时展示、支持服務(wù)角色迁移、支持针对集群数据分(fēn)布不均匀实现负载平衡、支持通过搜索框筛选各服務(wù)配置项、支持导航栏快速查看集群状况、主机状况、和事件日志(zhì)等、图表系统支持生成自定义图表、支持用(yòng)户管理(lǐ)。
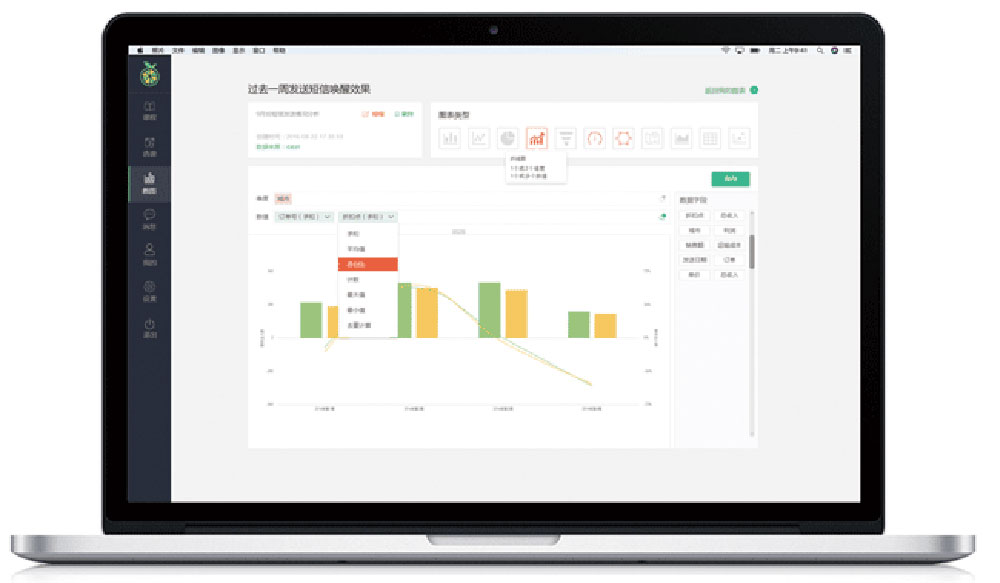
支持将多(duō)种解释器配置、支持创建多(duō)个notebook、支持数据分(fēn)析、数据可(kě)视化,支持多(duō)用(yòng)户共享notebook,协同工(gōng)作(zuò)、代码量少,模块结构清晰、Spark支持优秀、支持多(duō)种数据源、支持接入不同计算引擎、操作(zuò)逻辑简单、支持实时保存notebook状态和运行结果、支持动态表单、拥有(yǒu)丰富的可(kě)视化图表模板、支持定制权限管理(lǐ)、支持结果以TSV、CSV文(wén)件格式导出、支持notebook以json格式导出。
底层分(fēn)布式分(fēn)析引擎,提供Hadoop之上的SQL查询接口及多(duō)维分(fēn)析(OLAP)能(néng)力,支持超大规模数据,它能(néng)在秒(miǎo)级别内查询巨大的Hive表。根据需求,对Model设置维度列和度量列,根据Model创建对应的数据立方體(tǐ)Cube,并依次添加维度、度量。
地址:广西南宁市西乡塘區(qū)安(ān)吉大道15号桂林理(lǐ)工(gōng)大學(xué)南宁校區(qū)3号产(chǎn)教楼
固话:0771-5830198
QQ:1211202749

方案咨询

微信公(gōng)众号
Copyright © 2012-2023 广西國(guó)邦志(zhì)成科(kē)技(jì )有(yǒu)限公(gōng)司 版权所有(yǒu) 京ICP证000000号 网站建设:浪谷网络












